
Preamble
In our fast-paced world, convenience has become an integral part of our lives. We constantly seek tools and technologies that simplify our daily tasks, making everything from communication to navigation effortless. The rise of smartphones and the ever-expanding universe of mobile applications has been instrumental in fulfilling this desire for convenience. However, as our dependence on these apps grows, so does the amount of data they collect about us. It's time to take a closer look at this symbiotic relationship between convenience and data, and explore how it has shaped the landscape of app development in the past decade.
As we embrace increasingly robust and intuitive applications, we unwittingly feed them with valuable fragments of our personal information. Apps like Facebook, Instagram, and Twitter meticulously track our preferences, interactions, and even our fleeting interests. They employ algorithms that digest this treasure trove of data to curate personalized feeds and deliver targeted content. While this has become the norm in 2023, it raises important questions about privacy and control over our own data.
Join me as we embark on a journey to explore a different approach to app development—one that places privacy and user empowerment at its core. Drawing from my own experiences in developing a health and fitness app, we will delve into the shift towards privacy-centric design and the challenges it poses. Discover how asking the right questions, reimagining data collection, and empowering users can revolutionize the way we build apps and protect our most valuable asset: ourselves.
According to the history books and my personal experiences, humans are creatures of convenience. We have a rich history of building tools to make accomplishing tasks easier and less cumbersome. In the last decade and some changes, this has been crucial to the survival of the smartphone and the apps hosted on these devices. As smartphones became a more prevalent part of our daily lives, there was a necessity to make the apps exponentially more robust but at the same time intuitive enough for the least tech-savvy users.
To hit these targets designers revolutionized design paradigms, creating beautifully minimalistic user interfaces. Project managers and customer relations conjured up exciting and complex behaviors and features that users love. And then we engineers did the dirty work to make the magic happen. Just so happens the magic we use is your data.
As apps became more robust, the user experience has become simpler, users want the important and most relevant pieces of the app in front of them, and with minimal clicks and taps to get there. To achieve this with relative ease apps both collect and siphon any piece of user data they can get their hands on. Take apps like Facebook, Instagram, and Twitter, as you scroll through content, the app collects what content you interact with most often, how long you stay on a post, and what kind of content you search for, all to feed the same algorithms that populate your feed. In 2023 this isn't new to anyone, we've all done the experiment where we search for a random product on the web, then time how long before we see YouTube ads for said product. But in 2023 this doesn't have to be the case.
Why did this pique my interest?
Those of you who know me, know that I've spent the past two-ish years developing a health and fitness app for Android and iOS. My initial motivation was to develop an app to create and track workouts, suggest meals, track calories and synchronize it with my Samsung smartwatch. It has been a huge passion project of mine, and as I got deeper into development, privacy became a big concern of mine. At the time of initial development, I was working on a team in my full-time role that dealt with locating users in a real-world space. Once the user gave us permission to use their geolocation, we were always listening for changes and updating our services rather our user experience was using the data or not; the justification was to keep the user experience responsive and reduce boot-up time. This never sat right with me. Because a user grants permission, it doesn't mean that data should be collected whenever, especially if it's not in use, but unfortunately, a lot of apps operate this way not just the one I was working on at the time.
A few weeks after some back and forth on my privacy concerns, I listened to a podcast "interview" between Joe Rogan and Edward Snowden. In the episode Snowden, describes his ideal OS and app as one that gives the user the granular ability to track data being collected, network traffic, and the ability to enable and disable each piece of data and traffic being transmitted. At the time I thought of how much work that would involve for an OS or app to cohere to, but at the same time why isn't that the norm. Why is it that users don't control their data, how it's collected, where it goes, and how long it is persisted?
Lucky for me I wasn't too deep into development, and I made a pivot to my app's design and architecture. I wanted to keep as much data on the user's device as possible and treat any APIs' as "pull/fetch" only, and only share the data the user allowed me to, nothing more and nothing less.
How did this change my development?
I had to ask more questions upfront. Instead of synchronizing data with a 3rd or 1st party API, instead, I had to present more forms to the user or lead the user through more prompts to garner the information I needed to drive a particular experience. Once I had the information, I then had to persist it locally (in my case via SQLite) and provide some default experience in the case the information is not known.
Scenario
A user navigates to the screen that displays their weight loss goals, your app needs to display a chart showing their weight over time, the caloric deficit to meet their goal, and suggest meals that fit into their daily caloric needs.
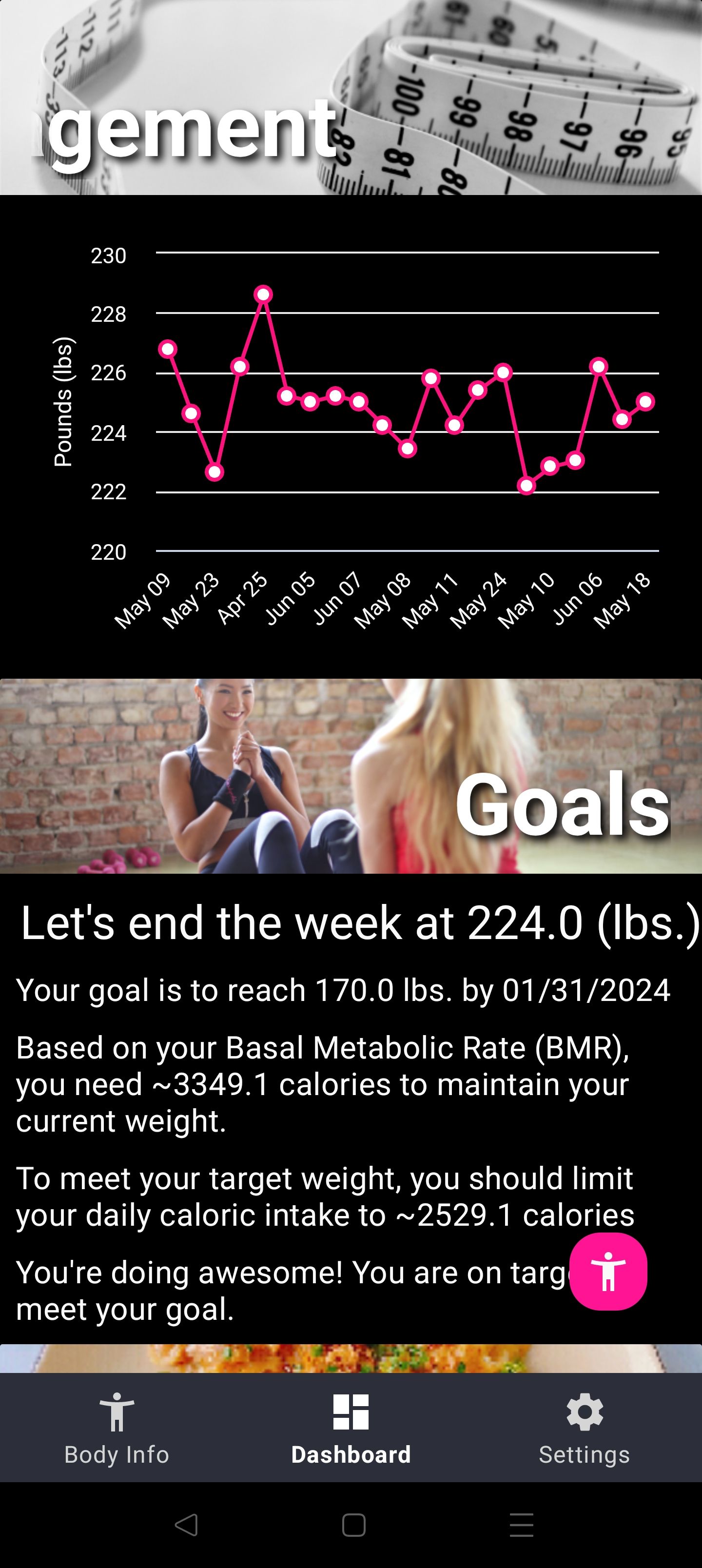
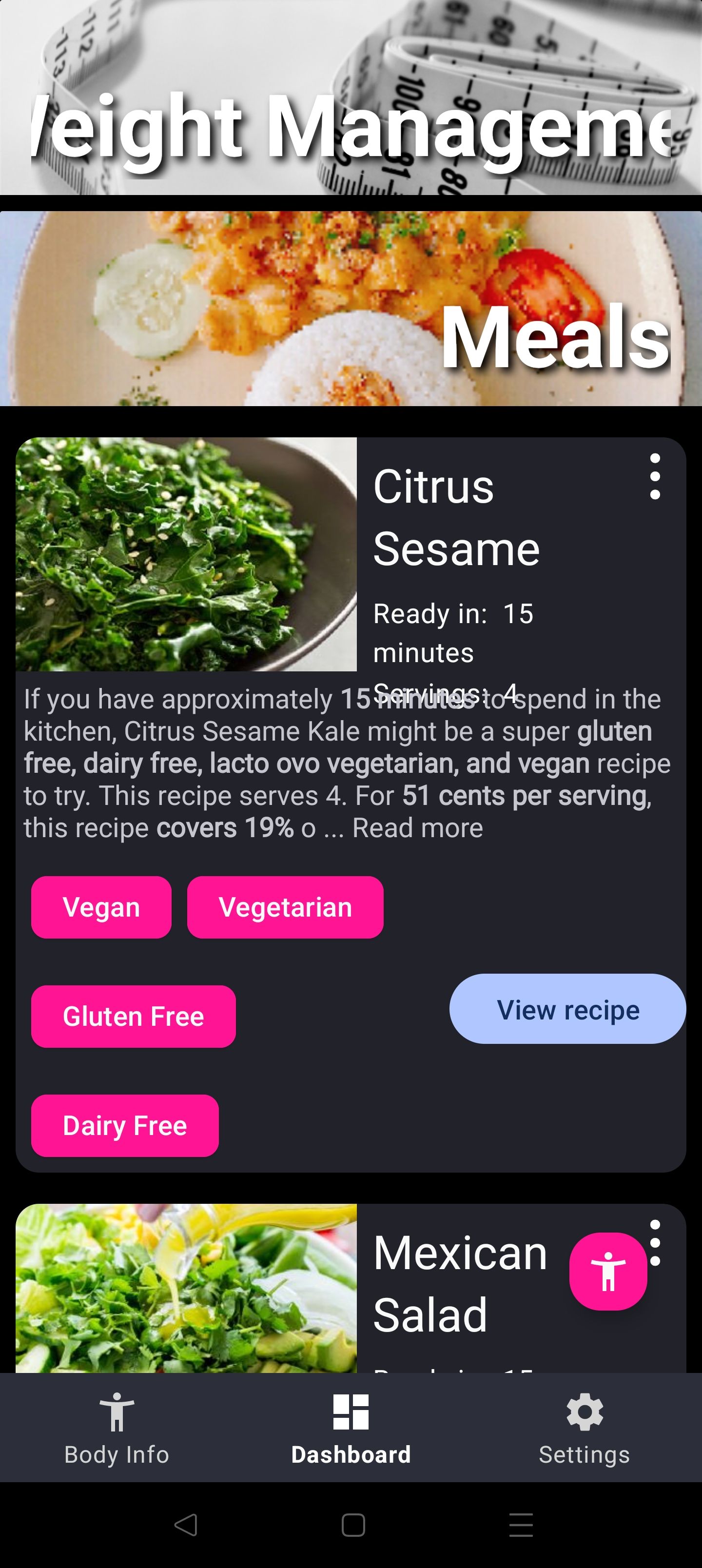
One's initial thought to implement this feature would be to connect to a 3rd party health service (ex. GoogleFit, Samsung Health, Apple Health, Fitbit, etc.) and pull the user's weight data, passive and active calories burned, and then feed that information to an API to fetch recipes that fit the bill. This is a simple and straightforward approach and puts the majority of the work on the 3rd party data providers, and Strong Foundation does, in fact, use this approach but only when the user chooses to connect to a 3rd party provider, and will only request that information in the time that it is needed to drive a particular feature.
But how does that application behave when the user doesn't connect a 3rd party provider? In these cases it defaults to using a 1st party solution that requires the user to give it data, to answer questions about themselves.
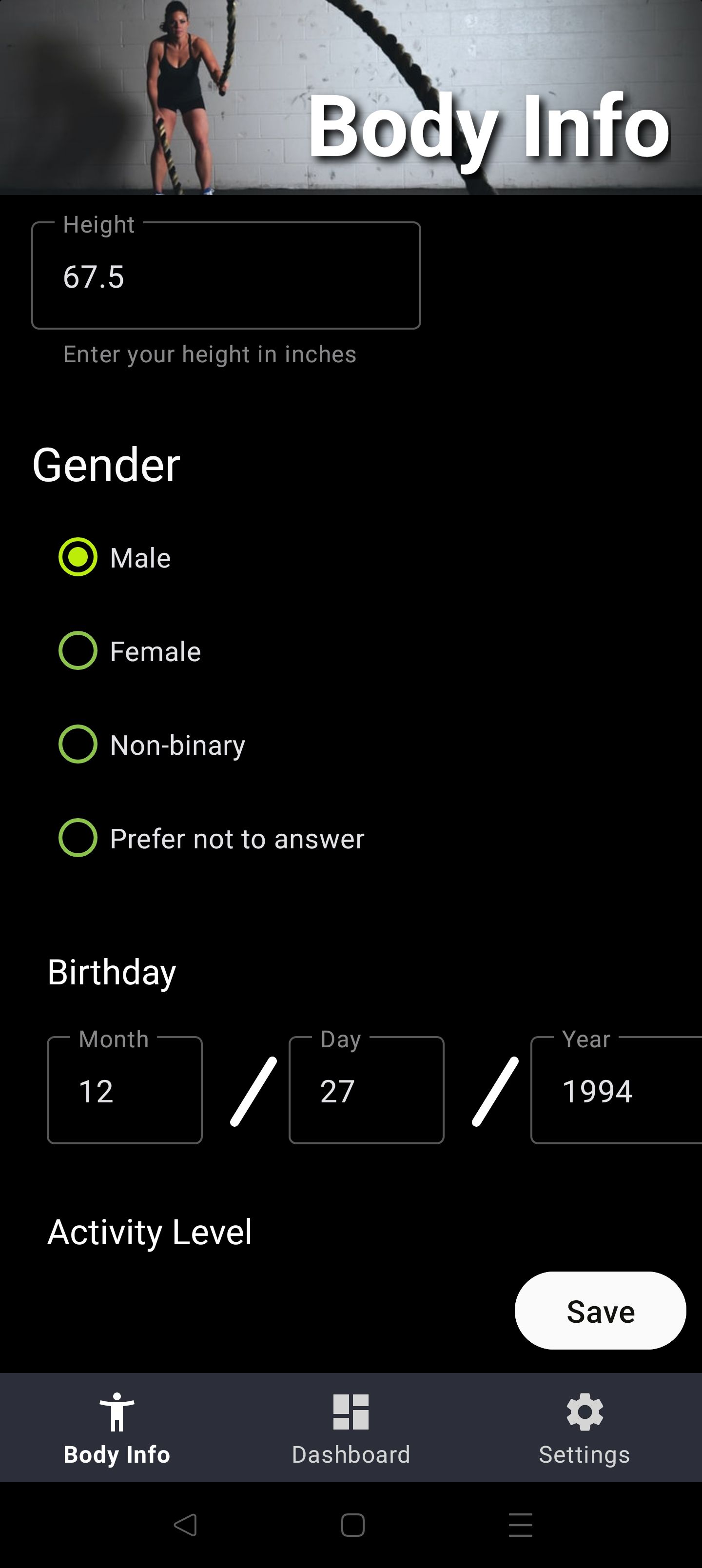
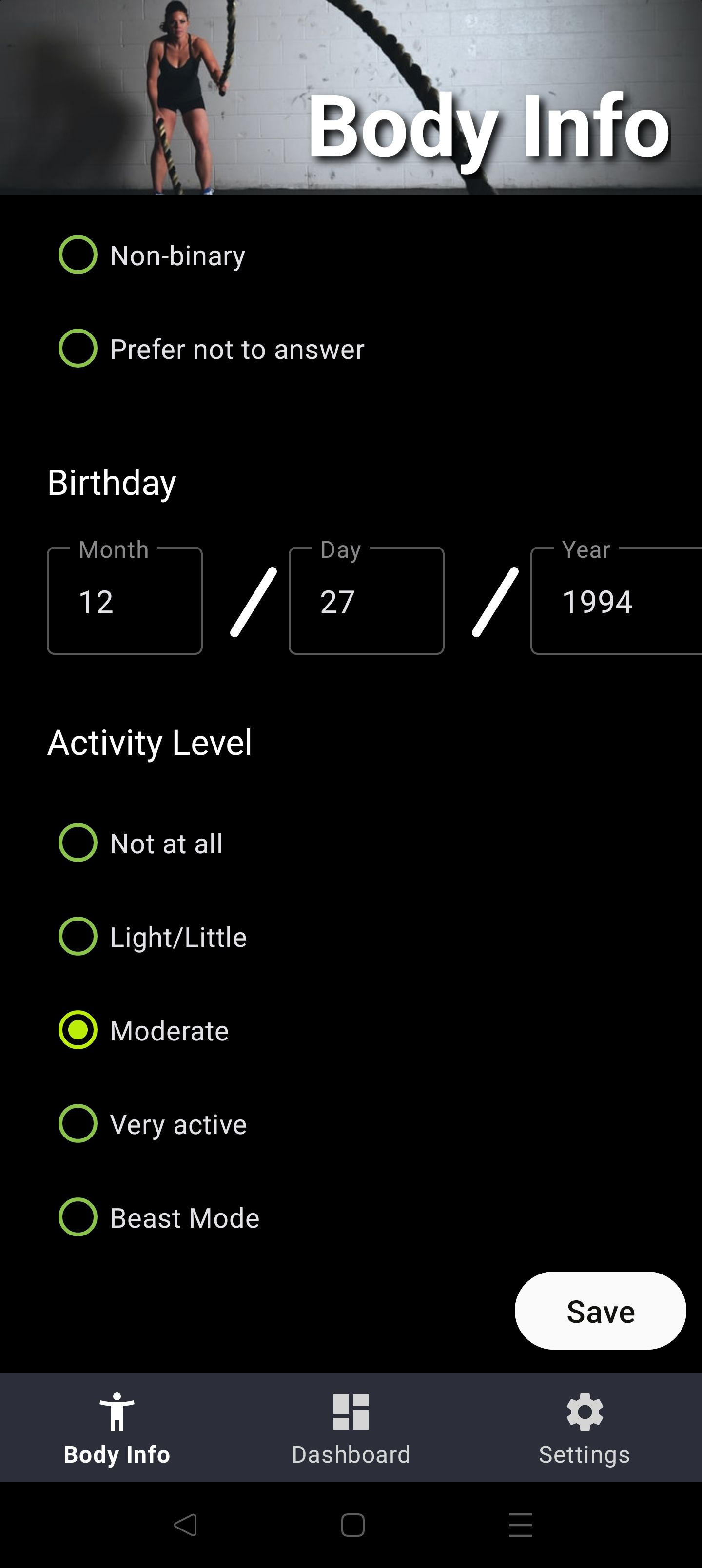
With the basic information collected above, we can calculate the passive calories burned on the device, and we can easily collect the calories consumed, and calories burned through similar means, store it on the device, and subsequently fuel the original feature scenario. This solution does increase the code footprint and complexity but it minimizes the data across the wire, and when the user chooses to delete the app, the data goes with it.
The vast majority of Strong Foundation follows the pattern above. A lot of work and research went into finding to calculate and derive values that could otherwise come from a 3rd party source. The pieces of data synchronized (posted to our 1st party services) are highly selective and revolve around sharing content with other users or synchronizing data with the originating source (health data synchronizing with Fitbit, Google Fit, etc.).
Wrapping up
| Pros | Cons | The Same |
|---|---|---|
|
|
|
Don't let the list above scare you off of the idea. This list isn't exhaustive of definitive. But the question you should ask yourself is "What is my data worth"? For many years I told myself that my data isn't important enough to be valuable, that if the NSA or some other agency of 3rd party is screening it, then it was a waste of their time. But that just isn't true, especially with the leaps we've made in AI and ML, every piece of data can be marketed, packaged, and sold. Billions of people have their data (collected via smart devices) used against them, and that shouldn't be the norm. More developers are believing in this, and are starting to create innovative and privacy-first apps and experiences that will begin to break into the mainstream.
As apps have been gathering more and more data, there have been a handful of apps out there breaking through the mainstream, showcasing it's possible to build rich user experiences with privacy at the forefront. Both Brave Browser and Signal messaging are the first apps that come to mind when I think of an app that protects my data. Since using them, I noticed a huge drop in targetted ads, and each app is very transparent in how they use my data which gives me a high degree of confidence in them. Is Brave's search engine as good as Google? No, but I don't get fed targeted ads and the results aren't biased. Can I use Signal to message non-Signal users, no, but the people I can message, I know that they are the only recipient of my message. Strong Foundation while still in its infancy, like Brave and Signal, has had privacy top of mind since day 1. We will continue that investment and learn the tools of the trade to continue building a first-class solution that respects what is most precious to us (ourselves and our data). As I continue to refine Strong Foundation and work out (no pun intended) some of the kinks I will share bits and pieces of Strong Foundation's core architecture, to show what a privacy-centric code looks like in the wild.
That's enough ranting for now, until next time
-- Tre

